Reading and writing a delimited and Fixed Length Files in ODI
In my last post Table to Table load I showed how to load a table from source to target. In this tutorial, I want to expand this to load a fixed length/delimited file to table and produce a fixed length/delimited file from table.
In this post, I will use a employees files which are similar to employees table in HR but the employee_id column will be missing in the file which we will generate through oracle sequence while loading into the table.
I have a comma delimited file and fixed length file. This is how they look like. They can be downloaded from here. CSV File Fixed Length


There are two tables which I will create in the target schema DATA_TARGET (which i created in table to table post) to hold the data loaded from csv file and fixed length file. Their DDL is shown below.
CREATE TABLE "DATA_TARGET"."EMPLOYEES_CSV" ( "EMPLOYEE_ID" NUMBER(6,0) NOT NULL ENABLE, "FIRST_NAME" VARCHAR2(20 BYTE), "LAST_NAME" VARCHAR2(25 BYTE) NOT NULL ENABLE, "EMAIL" VARCHAR2(25 BYTE) NOT NULL ENABLE, "PHONE_NUMBER" VARCHAR2(20 BYTE), "HIRE_DATE" DATE NOT NULL ENABLE, "JOB_ID" VARCHAR2(10 BYTE) NOT NULL ENABLE, "SALARY" NUMBER(8,2), "COMMISSION_PCT" NUMBER(2,2), "MANAGER_ID" NUMBER(6,0), "DEPARTMENT_ID" NUMBER(4,0), CONSTRAINT "EMPLOYEES_CSV_PK" PRIMARY KEY ("EMPLOYEE_ID") )CREATE TABLE "DATA_TARGET"."EMPLOYEES_FL" ( "EMPLOYEE_ID" NUMBER(6,0) NOT NULL ENABLE, "FIRST_NAME" VARCHAR2(20 BYTE), "LAST_NAME" VARCHAR2(25 BYTE) NOT NULL ENABLE, "EMAIL" VARCHAR2(25 BYTE) NOT NULL ENABLE, "PHONE_NUMBER" VARCHAR2(20 BYTE), "HIRE_DATE" DATE NOT NULL ENABLE, "JOB_ID" VARCHAR2(10 BYTE) NOT NULL ENABLE, "SALARY" NUMBER(8,2), "COMMISSION_PCT" NUMBER(2,2), "MANAGER_ID" NUMBER(6,0), "DEPARTMENT_ID" NUMBER(4,0), CONSTRAINT "EMPLOYEES_FL_PK" PRIMARY KEY ("EMPLOYEE_ID") )
Lets login to ODI repository now and configure the file information in Topology and create the model.
Topology and Model
Go to topology tab, expand File technology and select FILE_GENERIC data server (ODI provides it out of the box as it is not synonymous to database schemas but fitting it into odi architecture). Right click on file_generic and select new physical schema. Provide the directory where the file is residing in schema and work schema. Since I am going to have both csv and fixed length file in this directory, one physical schema is enough in this use case. If you are placing the fixed length file in different directory, you will have to create different physical schema for that here.

Now that we have data server and physical schema in place, lets create a logical schema. Create a new logical schema in logical architecture section under File technology. Right click on File and select new logical schema. Provide a name and select physical schema we created earlier for global context.

Lets now create a model. Go to designer tab and in the data model section, create a new model. Provide a name, select File technology and logical schema we created before and save it.

For files we can't do reverse engineering. we need to manually create the data stores (representation of file). It is going to be single model but will have different data store (file representation) for csv and fixed length file.
Right click on the data model we created and select new data store. In the definition tab Provide name, data store type as table and make sure that in resource name field exact file name is give. You can also use the search icon to select the file from directory.

Go to file tab. Provide file format as delimited, heading as 1 , field separator as comma and text delimiter as double quotes. Please make sure that heading number of lines provided otherwise first line will be considered as data and also when we reverse engineer for columns (coming up next), column names will not be identified.
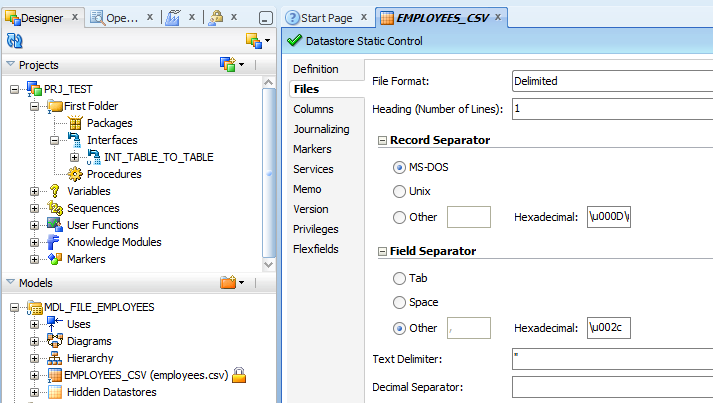
Go to columns tab. Click on reverse engineer. Since we provided first row as heading, it put the column names from heading columns. By default it identifies all data as string, we can convert them to respective data types while loading to table using database functions. Adjust the size it automated set as 50 if you think that field will have more characters. Save the csv data store.

Lets create a similar data store for fixed length file. But here it is driven by fixed length columns. Provide the details in definition tab.

Under files tab, provide fixed file format, head lines as 1 and fixed separator as space and text delimiter as double quotes.

Go to columns tab and click on reverse engineer. Popup will appear to decide the fixed length size of each columns here. If you are from Oracle SOA world, it would look similar to configuring file adapter. A vertical line will appear inside the dialog as you move your mouse on the scale, based on the size you need for the column, click and fix the length. If you play for sometime, you will be able to figure how it works if you are new to this.


Change column names from Cn to actual columns since it was not captured during reverse engineering. I have also specified the type as string as it was also not set by default.

We have completed the topology and model configuration for file. I will also reverse engineer the data_target model since we need the two new tables we created in data_target to appear in the model.
Right click on the model and select reverse engineer. Two new data stores will appear in the model.

Now that we have completed the model, lets create interfaces to load data from file to table.
Create Interfaces
I will use the same project for this post we created for Table to Table load. Lets create the sequence we are going use for loading and also import the file knowledge module before we create the interface in the project.
Under the project PRJ_TEST, right click on sequences and select new sequence. I am going to use the sequence which is available in HR schema even if we are not dealing with HR schema here. Thats the beauty of ODI that you can create your own ODI sequence or use native sequence from the respective technology.
Provide a name for sequence, select native sequence, select HR logical schema to get employee sequence in HR schema. save it.

Import the knowledge modules to load data from file and to file. LKM File to SQL is used to load data from file to table and IKM SQL to File Append is used to load data from table to file.
LKM File to SQL
IKM SQL to File Append

Lets create a Interface for CSV File to EMPLOYEES_CSV. Right click on interfaces and create a interface INT_CSV_TO_TABLE

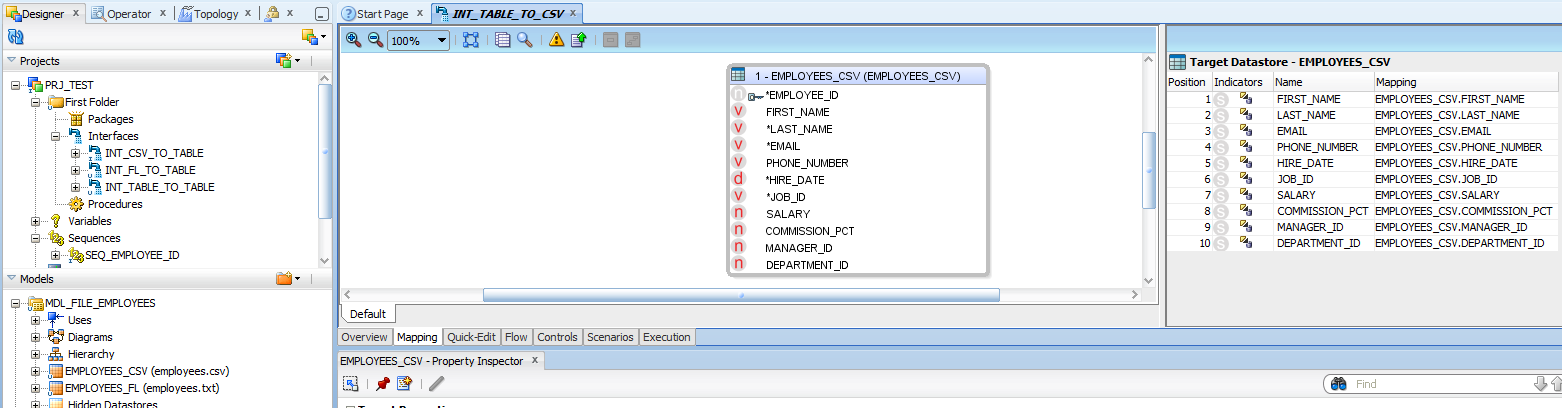
Go to mapping tab, drag an drop Employees_csv from file data model into source and employees_csv from data_target into target sections. Do the mapping from source field to target.

For the employees id field in target, select it and from the properties below, select the sequence for its value.

Go to flow tab, select target and make sure that IKM SQL Incremental update is selected to merge the rows into target (insert or update). We also use IKM SQL Control Append knowledge module if our requirement in just appending rows to target. LKM File to SQL is automatially selected since file is source here.

Go to control tab and check CKM Oracle is selected for constraints check. Save the interface.

Lets go ahead and run this interface to see the results. right click on this interface and run it with global context, no agent and desired log level. Go to operator tab and check the run results under All executions.
It is successful.

Lets check the target table for result data.

Lets create a similar interface for fixed length file. The steps are exactly same, the only difference is that in mapping tab, the source table is employees_fl of file model and target table is employees_fl of data_target model.

Lets run the interface INT_FL_TO_TABLE and verify results. This failed since the target column size is only 20 but my source has 30 as size. Either we can trim the mapping values for extra spaces through oracle functions and load it or increase the target column size here.

I went the path of adding functions as the actual data doesn't exceed the target field size but due to additional spaces and double quotes, the data size has increased. I have added functions replace(trim([field]),'",'') to remove double quotes and trim the spaces.

Lets run and check the output table. I could see the run is successful and output table is populated.

Lets create another two interfaces to load from table to file. There are couple differences between the previous interfaces from these two new interfaces.
1. source will table and target will be file
2. IKM SQL to File Append will be used to load the output file which will be selected in flow tab for target.
Let me show the mapping tab and flow tab for one interface here. Other steps are similar to what we have seen already. Also import the import point is that under definition tab, staging area different from target check box should be enabled and staging area logical schema need to be selected (data_target is selected in my case)
definition tab,

mapping tab,
Let's see the flow tab, here select target and select IKM SQL to File Append. Optionally we can select GENERATE_HEADER to true to generate headers in the file.

Lets run this this interface. Before that rename the existing files input directory to some other name so that they are not overwritten.
Run is successful and we can see the file in the output directory.


Follow the similar procedure for the table to fixed length file loading.
Another question comes to our mind is how do we specify the file name dynamically every time the interface is run for reading as well as writing?
Well. Variable comes to the rescue for this problem. Create a variable in ODI which has dynamic name for the file and once reverse engineering is done, we can specify this variable in place of the resource name in the data store. In the package we can refrench the variable and then the interface to take file name from variable in the interface. I will be covering procedure and package in my next posts. I will take a similar use case that time show the demo.
With this we have completed reading and writing delimited and fixed length files in ODI. In my next posts i will show reading writing complex files and xml and also introduce the procedure and package concepts.
Thanks for reading and let me know your comments and questions.
HI Muniyasamy,
ReplyDeletei need help for setting ckm for trasforing error records to E$ table.
My requirment is file to db,
i will get good records as well as bad records form file, i need to move the bad records to E$ table.
hum dil de chuke sanam
ReplyDeleteIn my CSV file has address column and does not have "" code for that column.how can we implement in ODI. Any setting has to set for data store level? . my file is comma(,) delimiter file.
ReplyDeleteI really appreciate the information shared above. It’s of great help. MaxMunus provides Remote Support For Corporate and for Individuals. If anyone is facing any issue in his project of # ORACLE DATA INTEGRATOR we can support them remotely , kindly contact us http://www.maxmunus.com/contact
ReplyDeleteMaxMunus Offer World Class Industry best Consultant on#ORACLE DATA INTEGRATOR. We provide end to end Remote Support on Projects. MaxMunus is successfully doing remote support for countries like India, USA, UK, Australia, Switzerland, Qatar, Saudi Arabia, Bangladesh, Bahrain, and UAE etc.
Saurabh
MaxMunus
E-mail: saurabh@maxmunus.com
Skype id: saurabhmaxmunus
Ph:(0) 8553576305/ 080 - 41103383
http://www.maxmunus.com
Hi , I want to load file from my remote server , local from my PC i am load file into oracle table , but trying to load data file from source server.
ReplyDeletePlease let me know what is the process for the same.
Hi
ReplyDeleteWe have one requirement which needs to be implemented in ODI 12C.
In ODI, in one of our target table, we upload data from csv file from one folder and its path is on linux machine, this file name contains timestamp in it...so every time source file name changes...so I want to read the file name and load in one of target table column..How can we achieve this?
Can you please share any document or link for this on email rishikeshk11@yahoo.co.in ?
Thank You.
If you are searching out repair to QuickBooks troubles, dial Quickbooks Customer Service Phone Number Help to solve your troubles speedy recovery.
ReplyDeletesamsun
ReplyDeleteurfa
uşak
van
yalova
HH2
https://saglamproxy.com
ReplyDeletemetin2 proxy
proxy satın al
knight online proxy
mobil proxy satın al
GWLQ
elazığ
ReplyDeleteerzincan
bayburt
tunceli
sakarya
QUV
https://titandijital.com.tr/
ReplyDeletekütahya parça eşya taşıma
siirt parça eşya taşıma
tekirdağ parça eşya taşıma
adana parça eşya taşıma
4K5MA3
B33E6
ReplyDeleteSiirt Evden Eve Nakliyat
Bursa Lojistik
Ağrı Parça Eşya Taşıma
Gümüşhane Parça Eşya Taşıma
Adıyaman Evden Eve Nakliyat
46613
ReplyDeleteYozgat Evden Eve Nakliyat
Isparta Lojistik
Hatay Evden Eve Nakliyat
Elazığ Lojistik
Bartın Parça Eşya Taşıma
CA1E5
ReplyDeleteEdirne Lojistik
Diyarbakır Şehirler Arası Nakliyat
Çanakkale Parça Eşya Taşıma
Niğde Parça Eşya Taşıma
Diyarbakır Evden Eve Nakliyat
Çorum Lojistik
Burdur Şehir İçi Nakliyat
Bilecik Şehirler Arası Nakliyat
Kars Şehir İçi Nakliyat
BB6D7
ReplyDeleteEdirne Parça Eşya Taşıma
Bitlis Şehirler Arası Nakliyat
Tokat Şehir İçi Nakliyat
Ardahan Parça Eşya Taşıma
Kütahya Şehir İçi Nakliyat
Antep Şehir İçi Nakliyat
Kilis Lojistik
Yalova Şehirler Arası Nakliyat
Hakkari Lojistik
627DA
ReplyDeleteBatman Şehirler Arası Nakliyat
Kocaeli Evden Eve Nakliyat
Ünye Organizasyon
Silivri Çatı Ustası
Kırıkkale Şehir İçi Nakliyat
Gümüşhane Lojistik
Mardin Şehirler Arası Nakliyat
Muğla Evden Eve Nakliyat
Ünye Çatı Ustası
C5E36
ReplyDeleteAntep Parça Eşya Taşıma
Niğde Evden Eve Nakliyat
Maraş Parça Eşya Taşıma
Giresun Şehir İçi Nakliyat
Bibox Güvenilir mi
Yozgat Evden Eve Nakliyat
Zonguldak Şehirler Arası Nakliyat
Çerkezköy Çelik Kapı
Kütahya Evden Eve Nakliyat
E4492
ReplyDeleteücretsiz sohbet
Kayseri Random Görüntülü Sohbet
telefonda kadınlarla sohbet
ankara en iyi ücretsiz görüntülü sohbet siteleri
bursa seslı sohbet sıtelerı
trabzon en iyi rastgele görüntülü sohbet
tunceli en iyi görüntülü sohbet uygulamaları
izmir rastgele sohbet uygulaması
kırklareli görüntülü sohbet sitesi
E7611
ReplyDeletekonya canlı görüntülü sohbet odaları
kırşehir bedava sohbet siteleri
bilecik ücretsiz sohbet uygulaması
bingöl sesli sohbet siteler
samsun canlı sohbet et
canlı sohbet siteleri
rastgele sohbet
van canlı görüntülü sohbet odaları
mersin görüntülü sohbet kızlarla
270E8
ReplyDeleteXcn Coin Hangi Borsada
Binance Borsası Güvenilir mi
Tumblr Beğeni Hilesi
Binance Borsası Güvenilir mi
Binance Para Kazanma
Omlira Coin Hangi Borsada
Tumblr Takipçi Hilesi
Tiktok Beğeni Hilesi
Btcst Coin Hangi Borsada
9C6B10F172
ReplyDeleteinstagram organik türk takipçi
B3A32DA16B
ReplyDeleteig takipçi
düşmeyen takipçi
bot takipçi satın al
Viking Rise Hediye Kodu
Binance Referans Kodu
Titan War Hediye Kodu
MMORPG Oyunlar
Dude Theft Wars Para Kodu
Call of Dragons Hediye Kodu
9C8E85BEFD
ReplyDeletePopular Now on Betting Sites
Popular Now on Betting Games
Play Casino Games Real Money
Best Betting Sites USA
Best Legal Online Gambling Sites
F68DA94DCB
ReplyDeleteTelegram Farm Botları
Telegram Farm Botları
Telegram Coin Botları
Telegram Para Kazanma
Binance Hesabi Acma
ReplyDeleteमहाकालसंहिता कामकलाकाली खण्ड पटल १५ - ameya jaywant narvekar कामकलाकाल्याः प्राणायुताक्षरी मन्त्रः
ओं ऐं ह्रीं श्रीं ह्रीं क्लीं हूं छूीं स्त्रीं फ्रें क्रों क्षौं आं स्फों स्वाहा कामकलाकालि, ह्रीं क्रीं ह्रीं ह्रीं ह्रीं हूं हूं ह्रीं ह्रीं ह्रीं क्रीं क्रीं क्रीं ठः ठः दक्षिणकालिके, ऐं क्रीं ह्रीं हूं स्त्री फ्रे स्त्रीं ख भद्रकालि हूं हूं फट् फट् नमः स्वाहा भद्रकालि ओं ह्रीं ह्रीं हूं हूं भगवति श्मशानकालि नरकङ्कालमालाधारिणि ह्रीं क्रीं कुणपभोजिनि फ्रें फ्रें स्वाहा श्मशानकालि क्रीं हूं ह्रीं स्त्रीं श्रीं क्लीं फट् स्वाहा कालकालि, ओं फ्रें सिद्धिकरालि ह्रीं ह्रीं हूं स्त्रीं फ्रें नमः स्वाहा गुह्यकालि, ओं ओं हूं ह्रीं फ्रें छ्रीं स्त्रीं श्रीं क्रों नमो धनकाल्यै विकरालरूपिणि धनं देहि देहि दापय दापय क्षं क्षां क्षिं क्षीं क्षं क्षं क्षं क्षं क्ष्लं क्ष क्ष क्ष क्ष क्षः क्रों क्रोः आं ह्रीं ह्रीं हूं हूं नमो नमः फट् स्वाहा धनकालिके, ओं ऐं क्लीं ह्रीं हूं सिद्धिकाल्यै नमः सिद्धिकालि, ह्रीं चण्डाट्टहासनि जगद्ग्रसनकारिणि नरमुण्डमालिनि चण्डकालिके क्लीं श्रीं हूं फ्रें स्त्रीं छ्रीं फट् फट् स्वाहा चण्डकालिके नमः कमलवासिन्यै स्वाहालक्ष्मि ओं श्रीं ह्रीं श्रीं कमले कमलालये प्रसीद प्रसीद श्रीं ह्रीं श्री महालक्ष्म्यै नमः महालक्ष्मि, ह्रीं नमो भगवति माहेश्वरि अन्नपूर्णे स्वाहा अन्नपूर्णे, ओं ह्रीं हूं उत्तिष्ठपुरुषि किं स्वपिषि भयं मे समुपस्थितं यदि शक्यमशक्यं वा क्रोधदुर्गे भगवति शमय स्वाहा हूं ह्रीं ओं, वनदुर्गे ह्रीं स्फुर स्फुर प्रस्फुर प्रस्फुर घोरघोरतरतनुरूपे चट चट प्रचट प्रचट कह कह रम रम बन्ध बन्ध घातय घातय हूं फट् विजयाघोरे, ह्रीं पद्मावति स्वाहा पद्मावति, महिषमर्दिनि स्वाहा महिषमर्दिनि, ओं दुर्गे दुर्गे रक्षिणि स्वाहा जयदुर्गे, ओं ह्रीं दुं दुर्गायै स्वाहा, ऐं ह्रीं श्रीं ओं नमो भगवत मातङ्गेश्वरि सर्वस्त्रीपुरुषवशङ्करि सर्वदुष्टमृगवशङ्करि सर्वग्रहवशङ्करि सर्वसत्त्ववशङ्कर सर्वजनमनोहरि सर्वमुखरञ्जिनि सर्वराजवशङ्करि ameya jaywant narvekar सर्वलोकममुं मे वशमानय स्वाहा, राजमातङ्ग उच्छिष्टमातङ्गिनि हूं ह्रीं ओं क्लीं स्वाहा उच्छिष्टमातङ्गि, उच्छिष्टचाण्डालिनि सुमुखि देवि महापिशाचिनि ह्रीं ठः ठः ठः उच्छिष्टचाण्डालिनि, ओं ह्रीं बगलामुखि सर्वदुष्टानां मुखं वाचं स्त म्भय जिह्वां कीलय कीलय बुद्धिं नाशय ह्रीं ओं स्वाहा बगले, ऐं श्रीं ह्रीं क्लीं धनलक्ष्मि ओं ह्रीं ऐं ह्रीं ओं सरस्वत्यै नमः सरस्वति, आ ह्रीं हूं भुवनेश्वरि, ओं ह्रीं श्रीं हूं क्लीं आं अश्वारूढायै फट् फट् स्वाहा अश्वारूढे, ओं ऐं ह्रीं नित्यक्लिन्ने मदद्रवे ऐं ह्रीं स्वाहा नित्यक्लिन्ने । स्त्रीं क्षमकलह्रहसयूं.... (बालाकूट)... (बगलाकूट )... ( त्वरिताकूट) जय भैरवि श्रीं ह्रीं ऐं ब्लूं ग्लौः अं आं इं राजदेवि राजलक्ष्मि ग्लं ग्लां ग्लिं ग्लीं ग्लुं ग्लूं ग्लं ग्लं ग्लू ग्लें ग्लैं ग्लों ग्लौं ग्ल: क्लीं श्रीं श्रीं ऐं ह्रीं क्लीं पौं राजराजेश्वरि ज्वल ज्वल शूलिनि दुष्टग्रहं ग्रस स्वाहा शूलिनि, ह्रीं महाचण्डयोगेश्वरि श्रीं श्रीं श्रीं फट् फट् फट् फट् फट् जय महाचण्ड- योगेश्वरि, श्रीं ह्रीं क्लीं प्लूं ऐं ह्रीं क्लीं पौं क्षीं क्लीं सिद्धिलक्ष्म्यै नमः क्लीं पौं ह्रीं ऐं राज्यसिद्धिलक्ष्मि ओं क्रः हूं आं क्रों स्त्रीं हूं क्षौं ह्रां फट्... ( त्वरिताकूट )... (नक्षत्र- कूट )... सकहलमक्षखवूं ... ( ग्रहकूट )... म्लकहक्षरस्त्री... (काम्यकूट)... यम्लवी... (पार्श्वकूट)... (कामकूट)... ग्लक्षकमहव्यऊं हहव्यकऊं मफ़लहलहखफूं म्लव्य्रवऊं.... (शङ्खकूट )... म्लक्षकसहहूं क्षम्लब्रसहस्हक्षक्लस्त्रीं रक्षलहमसहकब्रूं... (मत्स्यकूट ).... (त्रिशूलकूट)... झसखग्रमऊ हृक्ष्मली ह्रीं ह्रीं हूं क्लीं स्त्रीं ऐं क्रौं छ्री फ्रें क्रीं ग्लक्षक- महव्यऊ हूं अघोरे सिद्धिं मे देहि दापय स्वाहा अघोरे, ओं नमश्चा ameya jaywant narvekar